Ukraine War: An Online Corpus to analyze the impact of the War in Ukraine
System Architecture
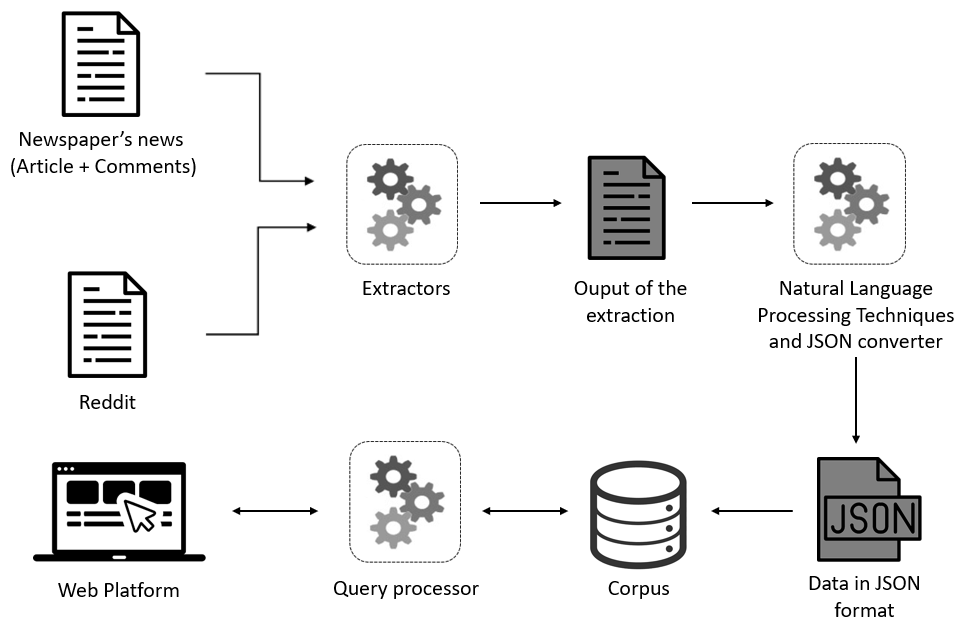
After the analysis of the texts selected from online newspapers and social media and the selection of the richest, an extractor is applied that extracts the desired information that is later stored in a file. In the following stage, the information is formatted and reduced to only what is essential using natural language processing techniques. Subsequently, the resulting information is converted to JSON format and then stored in a repository that will thus form the corpus. Finally, to explore the knowledge contained in the corpus, a query processor and Web platform will need to be developed. The query processor will take requests from users of the online platform, search the corpus, and then deliver the requested data.